
‘Big Data’ es el acto de recolectar numerosos bloques de información de fuentes tanto físicas como digitales para identificar tendencias y patrones que ayuden a la anticipación de cambios en nuestro entorno, detección de oportunidades y mejora en la toma de decisiones. Tal cual.
La información es usada por las empresas para acrecentar su conocimiento sobre sus usuarios y clientes, lo que estos quieren y sus necesidades. Es más, la mayor parte de los datos recopilados hoy en día son generados por ellos mismos, los consumidores.
El objetivo final consiste en tomar decisiones sólidas, respaldadas en datos «tangibles» y no en mera intuición, aunque a veces sea muy válida.
Pero, ¿de dónde viene toda esta información? Actualmente, de todas partes: encuestas físicas que luego se trasladan a bases de datos, clics en pistas de audio, reproducciones de vídeos en streaming, logins en cualquier web en la que tengamos cuenta… Absolutamente todos nuestros actos en la red se convierten en información almacenable con disposición a ser tratada.
En definitiva, el ‘Big Data’ traduce un vasto conjunto de información en valor para la empresa.
Esta afirmación se refleja de manera fiel en la ‘Pirámide del Conocimiento’ o ‘Jerarquía DIKW’ por sus siglas en inglés (Data, Information, Knowledge, Wisdom).
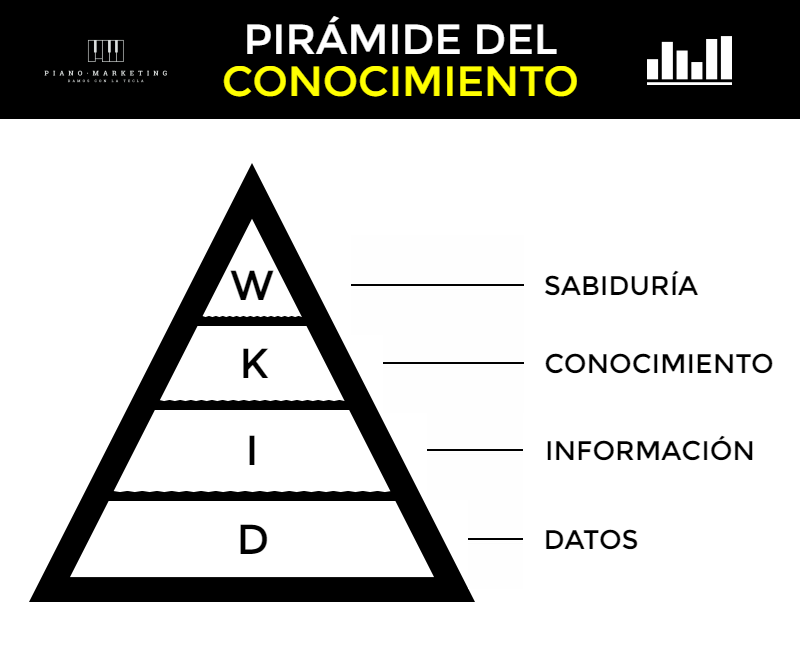 Los datos describen y representan hechos empíricos. La información es un conjunto organizado de datos donde estos se ordenan y cobran sentido. Cuanta mayor información tengamos, mayor será nuestro conocimiento. La sabiduría es el entendimiento inteligente del conocimiento, que nos posibilita reflexionar y sacar conclusiones con aplicaciones prácticas.
Los datos describen y representan hechos empíricos. La información es un conjunto organizado de datos donde estos se ordenan y cobran sentido. Cuanta mayor información tengamos, mayor será nuestro conocimiento. La sabiduría es el entendimiento inteligente del conocimiento, que nos posibilita reflexionar y sacar conclusiones con aplicaciones prácticas.
Pero, ¿para qué queremos datos si no escuchamos lo que nos dicen?
Tipos de informaciones que trata el ‘Big Data’
Como su propio nombre indica, ‘Big Data’ apunta a las masivas cantidades de información que se aprestan a ser tratadas para exprimirle todo su jugo. Pero existen numerosos tipos de informaciones, que vamos a clasificar en 3 grandes grupos clave: origen, tiempo y estructura.
ORIGEN: la información puede ser interna o externa dependiendo de si proviene de nuestra propia empresa o desde fuera.
En el primer caso, la conveniencia de analizar datos estriba directamente en agilizar la estructura organizacional, lo cual atañe a todos los procesos que se gestionan a nivel interno.
En la segunda opción, puede provenir desde cualquier fuente externa, ya sea cliente, socio o un desconocido cualquiera que nos menciona en redes sociales, importantísimas dentro del ‘Big Data’.
TIEMPO: el análisis de la información puede ser en ‘batch time’ o en ‘real time’.
‘Bach time’ significa que los datos recibidos son guardados de forma automática durante un determinado periodo de tiempo para ser analizados a posteriori y mejorar el conocimiento que se tiene de la empresa. Este proceso se encuentra estrechamente relacionado con el concepto de ‘Business Intelligence’ o ‘Inteligencia Competitiva’, como veremos ahora.
- Ejemplo: una cámara recoge un elevado número de accidentes en un determinado tramo de una carretera en el mes de marzo. Entonces, se analiza tras ese mes y se estipula si esa carretera necesita unas medidas superiores de seguridad.
‘Real time’ significa que los datos se analizan conforme estos van llegando, al unísono o de la forma más precoz posible. Es lo que se conoce como ‘Fast Data’. Ni más ni menos que ‘Big Data’ en tiempo real, y trabaja bajo la ciencia de la ‘Analítica Predictiva’ tratando cambiar el rumbo de la situación a la vez que un suceso o fenómeno está ocurriendo.
- Ejemplo: la cámara que te multa por exceso de velocidad. En cuestión de 1 segundo o menos detecta si ibas respetando la señal o no y al mismo tiempo procesa los datos del recibo que te llegará en los próximos días. Se trata de un ciclo en tiempo real, instantáneo.
ESTRUCTURA: llegamos a uno de los puntos más importantes del ‘Big Data’ y donde se centra el fuerte de esta noción. Los datos pueden ser estructurados, semi-estructurados y no estructurados.
Datos estructurados: son los datos «fáciles» de analizar, ya que son aquellos generados de manera predefinida por un sistema, como los registros en tablas, sencillas como Excel, o ficheros asociados a un esquema XML o SQL (lenguaje de consulta estructurada). En castellano, aquellos que están organizados en bases de datos que permiten la recuperación de información de manera muy sencilla introduciendo unos determinados parámetros de búsqueda.
- Como ejemplos tenemos las valoraciones de usuario, de un restaurante o un hotel en TripAdvisor o Booking o de una película en Filmaffinity o Netflix, los movimientos de una cuenta bancaria, o los datos compilados en servicios públicos como el INE, entre otros.
Datos no estructurados: y llegamos al kit de la cuestión. Los datos no estructurados no se pueden almacenar de forma estándar, necesitan de software especial no relacional capaz de hacer consultas ad-hoc (a medida) como las bases de datos NoSQL o marcos Apache Hadoop, donde IBM Analytics está realizando un trabajo descomunal.
El principal problema de estos datos es que en su mayor medida son generados directa o indirectamente por el usuario. No los vuelca en un fichero con unos campos a completar, sino que directamente los crea sin un patrón definido, lo cual es lo que trata de averiguar el ‘Big Data’.
- En este caso encontramos ejemplos en una ruta tanto haciendo deporte físico como trazando un camino en coche que requiere de GPS, el tráfico web de una página a otra cualquiera o de e-mails, las reacciones de usuarios en forma de comentarios en YouTube, o las publicaciones en redes sociales, donde se trata incluso de obtener el significado de una foto subida sin texto alguno.
Datos semi-estructurados: por último, tenemos los datos semi-estructurados o híbridos, que tocan ambos terrenos. Las bases de datos no relacionales, aun siendo más complejas, no sustituyen a las relacionales puesto que las segundas están diseñadas para consultas ágiles que las primeras no tienen capacidad de hacer con la misma eficiencia.
- Como ejemplo tenemos el envío de un paquete a través de una empresa de mensajería o logística, donde se nos pide completar nuestros datos (estructurados) y después redactar en la caja de especificaciones nuestra preferencia en la hora de recogida (no estructurados): SEUR, Amazon, etc.
Según la revista especializada en finanzas Forbes, para una gran compañía como las que este medio enlista el solo hecho de tratar un 10% más de la información que recibe le reportaría unos ingresos superiores a 65 millones de dólares. No suena mal, ¿no?
La adopción del ‘Big Data’ en todo el tejido empresarial comienza a notarse. Aquellas empresas con recursos suficientes ya dedican presupuestos millonarios en proyectos de este tipo. El futuro del ‘Big Data’ cada vez más relacionado con el mundo de los negocios.
Al final, cuanta más información se analiza mejor experiencia de usuario puede trasladarse.
‘Big Data’ y su relación con la ‘Inteligencia Competitiva’
Comúnmente se ha relacionado el término ‘Big Data’ con las empresas tecnológicas y la tecnología en general. Esta creencia no es del todo cierta, a pesar de que prácticamente todas las entidades relativas a este campo de la ciencia requieren del tratamiento masivo de información para la viabilidad de su modelo de negocio.
Cuando descargas e instalas una «app» sin leerte los términos y condiciones de uso, automáticamente estás entrando en el «juego» del ‘Big Data’.
Cualquier sector es susceptible de ser asociado con el ‘Big Data’, ya que la ‘Inteligencia Competitiva’ (o ‘Business Inteligence’), vista como el conjunto de actividades dirigidas a la colecta, trata y difusión de información útil a efectos de su explotación económica, puede ligarse con cualquier empresa que esté dispuesta a maximizar el usufructo del volumen de datos que genera.
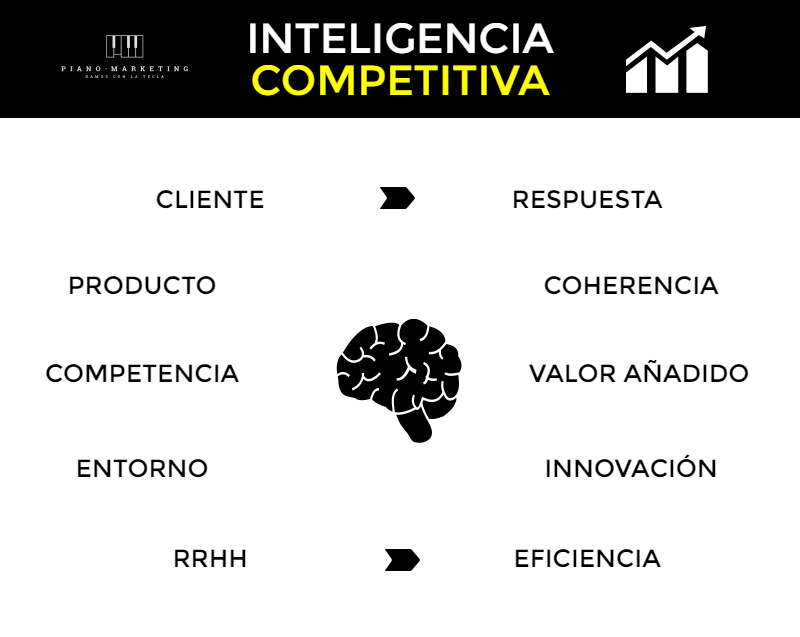 La ‘Inteligencia Competitiva‘ abarca 5 dimensiones que, tras ser licuadas, permiten la obtención de una serie de propiedades que bien aprovechadas pueden otorgar no solo un mayor entendimiento de la propia empresa y del sector, sino ir un paso más allá: la ventaja competitiva.
La ‘Inteligencia Competitiva‘ abarca 5 dimensiones que, tras ser licuadas, permiten la obtención de una serie de propiedades que bien aprovechadas pueden otorgar no solo un mayor entendimiento de la propia empresa y del sector, sino ir un paso más allá: la ventaja competitiva.
Cliente: puede darse una respuesta más adecuada a sus necesidades analizando lo que quiere.
Producto: puede observarse si existe coherencia entre lo que se promete dar y lo que finalmente se oferta.
Competencia: estudiando sus acciones, se puede ofrecer un valor añadido diferencial que nos posibilite satisfacer y fidelizar al cliente mejor que los competidores.
Entorno: investigando nuestro alrededor se puede desarrollar innovaciones, aun siendo a pequeña escala, que los demás no estén realizando y eregirnos en líderes tecnológicos (salvando distancias).
Recursos Humanos: si se cuida al trabajador, éste cuidará del cliente, por tanto en primera instancia el valor de nuestra fuerza productiva es fundamental. Examinando su comportamiento, pueden detectarse mejoras en su productividad y lograr una mayor eficiencia en sus procesos.
El conocimiento es poder y éste reside en el dato, por tanto sin su análisis tenemos un conocimiento muy valioso al alcance de nuestras manos que nunca llegaremos a tocar.
Como alude el tecnólogo Jhon Naisbitt:
«Nos ahogamos en informaciones pero pasamos hambre de conocimientos».
Las 4 V’s del ‘Big Data’
A su vez, el ‘Big Data‘ se ha venido configurando mediante 3 dimensiones: Volumen, Variedad y Velocidad, que no son nada sin la más reciente de las incorporaciones y que cada vez adquiere mayor peso dentro del análisis de datos: la Veracidad.
Todo negocio, ya no que se precie, sino que quiera sobrevivir, debería conocerlas y saber qué tipo de datos recibe para categorizarlos apropiadamente y poder tratarlos de acuerdo a su estructura de la manera más conveniente. De este modo:
Volumen: hace referencia a la cantidad masiva de datos que se intenta aprovechar para mejorar la toma de decisiones. En grandes entornos se habla de petabytes y zetabytes, estimándose entrar en el terreno de los zettabytes en la próxima década.
Sin embargo, cada empresa debe cuantificar su propio cupo de datos para agrupar la información de la mejor forma posible. 1 zettabyte (ZB) es el equivalente a 1 billón de gigabytes (GB). Actualmente suena inalcazable e incluso ridículo. Pronto nos habremos acostumbrado.
 Variedad: esta dimensión tiene que ver con gestionar la complejidad de múltiples tipos de datos, yendo desde los estructurados hasta los no estructurados, como comentábamos anteriormente.
Variedad: esta dimensión tiene que ver con gestionar la complejidad de múltiples tipos de datos, yendo desde los estructurados hasta los no estructurados, como comentábamos anteriormente.
- La tecnología es indispensable en este aspecto, en un futuro no muy lejano la información tradicional arrancará las lágrimas de lo más nostálgicos, abrumados en un mar de contenido digital: datos de texto, datos web, archivos de registro, tweets, por enumerar unos pocos…
Velocidad: hace alusión a la velocidad con la que se crean, procesan y analizan los datos. Estos se analizan de forma retrospectiva, a toro pasado, de forma que podamos predecir patrones y corregir rumbos equívocos en la empresa o ineficientes en un futuro a corto/medio plazo.
Pero los datos están en movimiento y cada vez corren más. Recuperando la referencia anterior, así nace el concepto de ‘Fast Data’, el hecho de analizar la información en tiempo real, en streaming, para poder tomar decisiones casi instantáneas.
- Esta variante ultra rápida del ‘Big Data’ tiene una aplicación y potencial tremendo. Puede utilizarse en ámbitos muy diversos, desde remarketing en mercadotecnia hasta la evitación de un fraude en una entidad bancaria o un e-commerce, donde el dato debe saberse en ese preciso momento y no a posteriori.
Veracidad: la cuarta V expresa el nivel de fiabilidad asociado a ciertos tipos de datos. Este parámetro pretende limpiar el dato que se obtiene para darle utilidad en su forma más pura y no confundirlo o malinterpretarlo, pero es uno de los retos más difíciles que tiene el ‘Big Data’ por delante y que aún debe pulir.
- Por ejemplo, las previsiones meteorológicas o los cambios en la bolsa. Aun existiendo pronósticos en tiempo real ningún sistema informático es capaz todavía de determinar con exactitud si el dato obtenido puede ser merecedor de una total confianza para actuar en función del mismo.
Aquí es donde nuestra capacidad como seres humanos entra en juego. La única certeza acerca de la incertidumbre es que ésta nunca desaparecerá al 100%. En la era del ‘Big Data’ el pensamiento crítico se alzará como una de las cualidades a poseer más importantes en nuestro tiempo.
Dejar un comentario